Knowledge Graph (KG) Context in Deep Learning Approaches
This blog post was written by Isaiah Onando Mulang’.
Part 1 : Encoding KG Aliases in Attentive Neural Network for Entity Linking (ARJUN)
Entity Linking is a long task in NLP dating from 2006, but really picked up around 2010 with Systems such as Ferragina P. & Scaiella U. ‘s TAGME, and P.N. Mendes et. al. ‘s DBpedia Spotlight among the very first initiatives. When Hoffart et. al. released the data set on CONLL-AIDA dataset; aligning the 2003 CONLL NER dataset with Entities in Wikipedia, there was a little burst in attention to this research task. Over a long time, systems sought to achieve better performance on this dataset, the Wiki Disambiguation Dataset (released with TAGME), and other DBpedia based datasets like the RSS-500 dataset of news excerpts annotated against DBpedia and encoded in NIF format Usbeck et al., 2015 seeing the introduction of techniques such as Graph Traversal, Neural Networks etc. Have a peep at the Krisztian Balog’s survey for a better historical journey as well as Ozge Sevgili et. al.’s review of Neural Network based techniques . Of course there are other datasets that appeared in this domain as early as 2007 : MSNBC, ACQUAINT, based majorly on Wikipedia, DBpedia and News Articles. A lot of work also went into the Freebase wave (remember her?), and she keeps her fingerprints todate, especially in KG completion tasks.
Why does Wikidata suddenly look like a new superpower KG?
As you can see, there is limited research, historically, targeting Wikidata KG. However this is beginning to change, since Wikidata is currently attracting attention from research communities. Wikidata has been observed as a rich source of structured data with almost all entities in Wikipedia present in the KG, just a little bit more structured according to the Hyper-labeled Graph structure. The structure of Wikidata that allows for representation of richer relations, as well as the fact that Wikidata is crowd authored not only affords richer information but also introduces several challenges. When users author entities and relations in the graph, there is much more and richer information represented but equally, these users do not follow strict standards. Clearly, this leads to duplicate naming, long titles (some even obscene) etc. Disambiguation of Entities in this kind of environment is a special case. For example: Berlin, is the famous capital city of Germany. In Wikidata KG, there are about 5 entities labeled as Berlin; including 3 towns in the USA called with this name. Each of Oregon, Massachusetts, Nevada, Ohio, and many more states have a town called Berlin. In the Wikidata KG, all of these would be represented with the label: “Berlin” in contrast to DBpedia for instance that would represent the same in a special format “Berlin_Township,_New_Jersey” to differentiate from the other Berlin. The figure below show a few of the challenges that exist in linking entities ti Wikidata KG, listed as S1, S2, and S3, to depict different sample sentences with different challenge complexity.

Datasets: Then, there is the issue of Datasets. You see, traditionally, Entity Linking datasets were based on Wikipedia, then came YAGO and DBpedia (For DBpedia you must also consider the 8yr running task of QALD datasets which were easily adaptable for EL). Only recently has these datasets been aligned to the Wikidata KG (e.g. the AIDA-CONNL dataset has now been aligned with Wikidata), while at the same time Hady Elsahar et.al. 2018 introduced the T-Rex dataset, first dataset purely based on Wikidata entities. Antonin Delpeuch’s Open Tapioca aligns the RSS dataset by Ricardo and co. to Wikidata entities and introduces a new Wikidata-based dataset (ISTEX) as well. Alberto Cetoli et. al. in 2019 generated a new dataset from the Wiki-Disamb30 by aligning it with wikidata based on Wikipedia-Wikidata links and augmenting every positive example with a closely related negative example, the resultant dataset is termed as Wikidata-Disamb. Observe that this late influx, migration and realignment indicates some peculiarity of Wikidata KG as earlier discussed.
So why bother about Entity Context in Attentive Neural Networks?
ARJUN (as we call our approach employed in this work) seeks to leverage only one form of information available in Wikidata about entities i.e. labels and their aliases. This has also been a common practice lately in several research tasks (take a trip for example to the use of “side information for Relation Extraction” in the paper RESIDE, and on your way back, for the Entity Disambiguation task; check the deep typing information in Raiman and Raiman, as well as Alberto Cetoli et. al.2019. FALCON was the first tool to employ KG context in Entity and relation linking albeit using linguistic rules. The aim of ARJUN is however, to demonstrate the importance of such information in the EL task, as well as how to add them as signals in a Neural network setting. Using a single neural network to achieve the end to end EL task, would not lend itself well to allow additional information, likewise, the recently observed Transformer models like BERT and XLNet, are limited in the amount of information you can add during finetuning, whereas pretraining is resource intensive. As such ARJUN employs two attentive neural network models, where the first model carries out NER while the second model performs NED. This is an approach to break the blackbox of Neural Networks and introduce extra signals at the interchange.
Use of [Local] Background KGs
FALCON, introduced the concept of a local KG where entity and relation names from a KG are augmented by aliases; and same as entities from other KGs (Visavis Wikidata & DBpedia). A local BG-KG is basically a bi-partite graph where pairs of entity names, aliases and synonym information is represented. Arjun utilizes a local KG at the interchange, to build entity context for the Disambiguation model. You will see from the approach diagram below,
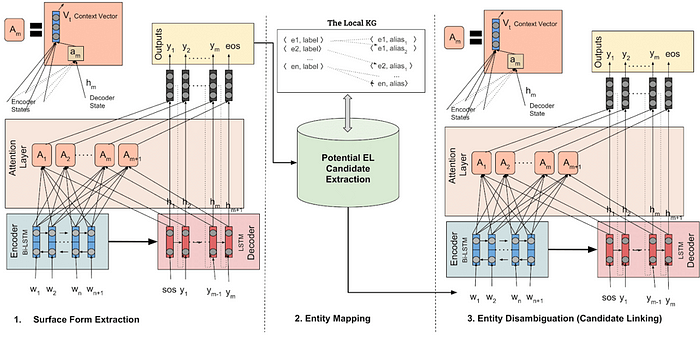
Arjun achieves 0.77 F-Score for the surface form extraction task and identifies the correct surface form for the kind of exemplary sentence shown in challenges of Wikidata (i.e. ASIC in sentence S1) and links it to the entity label “Application Specific Integrated Circuit” wdt:Q217302. The baseline can not achieve the linking for this sentence. In the Local KG, the entity label of wdt:Q217302 is enriched with aliases that also contain the form “ASIC”. This also allows Arjun to provide the correct linking to the Wikidata entities containing long labels. For example, in the sentence ”The treaty of London or London convention …” links the surface form London convention with the label Convention on the Prevention of Marine Pollution by Dumping of Wastes and Other Matter (c.f. wiki:Q1156234). The entity label has 14 words, and Arjun provides correct linking.
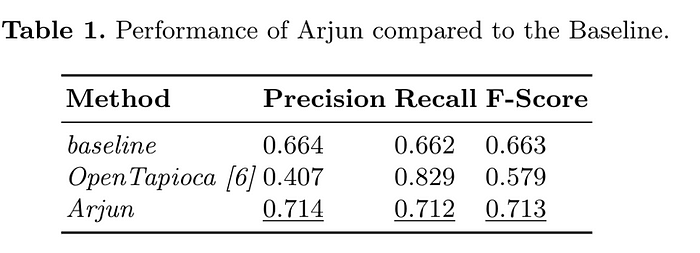
The performance of Arjun is shown in table 1 above, where there is clear indication that KG context has good improvement in the performance of the model. Some of the limitations of Arjun are brought about by the fact that the mention detection performs at 0.77 F-score which in turn becomes a cap for the disambiguation model. Likewise, the local KG, uses elastic search BM25 with fuzzy matching, we believe this can be improved to generate better entity candidates for instance the sentence: “Two vessels have borne the name HMS Heureux, both of them captured from the French” has two gold standard entities (Heureux to French ship Heureux (wiki:Q3134963) and French to French (wiki:Q150)). Arjun links Heureux to L’Heureux (wiki:Q56539239). Likewise a better approach for the mention detection component (especially with the current Transformer based models) will improve the performance of the model.
Link to the paper: https://arxiv.org/pdf/1912.06214.pdf
